CV10 – Explorační analýza dat, deterministické interpolační metody
Explorační analýza dat
Explorační analýzou dat obecně rozumíme souhrn statistických metod používaných pro průzkum dat. Měla by být provedena vždy před přistoupením k samotné práci s daty. Mezi její základní operace ve vztahu k použití v GIS patří:
- studium statistického rozdělení datového souboru
- identifikace odlehlých hodnot, hledání jejich důvodu, případná eliminace
- identifikace globálních trendů ve vývoji hodnot
Zde jsou některé základní metody a nástroje používané při EDA:
1. Deskriptivní statistika
- Souhrnné statistiky: Zahrnují měření jako průměr, medián, rozptyl, standardní odchylka, minimum a maximum.
- Frekvenční tabulky: Tabulky, které ukazují, jak často se určité hodnoty vyskytují.
2. Vizualizace dat
- Histogramy: Grafy, které ukazují rozložení dat podle tříd.
- Box ploty (krabicové diagramy): Grafy, které zobrazují rozložení dat a identifikují odlehlé hodnoty (outliers)
- Scatter ploty (rozptylové diagramy): Grafy, které ukazují vztah mezi dvěma proměnnými.
- Časové řady: Grafy, které ukazují, jak se data mění v čase.
- Teplotní mapy (Heatmaps): Grafy, které zobrazují intenzitu hodnot na dvourozměrném prostoru.
3. Prostorová analýza
- Prostorová vizualizace: Použití map pro zobrazení prostorových dat a identifikaci geografických vzorů.
- Hot Spot Analysis: Identifikace oblastí s vysokou nebo nízkou koncentrací hodnot.
Deterministické interpolační metody
Deterministické interpolační metody jsou techniky, které vytvářejí odhady hodnot v neznámých místech na základě známých hodnot v okolních bodech. Tyto metody jsou založeny na explicitních matematických vztazích a předpokladech o datech.
1. Inverse Distance Weighting (IDW)
- Princip: IDW předpokládá, že hodnoty bodů, které jsou blíže k neznámému bodu, mají větší vliv na interpolovanou hodnotu než body vzdálenější. Vypočítává vážený průměr hodnot okolních bodů, přičemž váhy jsou převrácené hodnoty vzdáleností.
- Vlastnosti: Výsledky jsou hladké, ale mohou obsahovat hrany nebo skoky, pokud jsou data nerovnoměrně rozložena. IDW je vhodný pro situace, kde je např. znečištění vzduchu nebo teplota výrazněji ovlivněna blízkými hodnotami než vzdálenějšími.
2. Spline
- Princip: Spline metoda využívá matematické funkce k vytvoření hladkého povrchu, který prochází přes všechny známé body. Existují různé varianty spline, jako je Regularized a Tension.
- Regularized Spline: Produkuje hladší povrch, který minimalizuje zakřivení.
- Tension Spline: Umožňuje kontrolu nad hladkostí povrchu, kde vyšší hodnoty napětí produkují méně hladký povrch.
- Vlastnosti: Spline metody jsou užitečné pro data, která se mění hladce, jako je teplota nebo vlhkost. Tato metoda se snaží minimalizovat celkovou zakřivenost povrchu.
3. Natural Neighbor
- Princip: Natural Neighbor interpolace hledá nejbližší sousedy pro daný bod a používá Voronoiho diagram k určení váhových faktorů pro tyto sousední body. Hodnoty interpolovaných bodů jsou váženým průměrem hodnot jejich nejbližších sousedů.
- Vlastnosti: Tato metoda je velmi efektivní a poskytuje hladké výsledky bez nutnosti nastavení parametrů. Natural Neighbor je ideální pro data s nepravidelným rozmístěním, protože využívá pouze okolní body.
Zadání cvičení:
- z vrstvy průměrných teplot v souboru mean2014_2023.nc si vyberte datum prosinec 2014 a vyexportujte si toto datum do samostatného rastrového souboru
- na území České republiky si vygenerujte náhodně 100 bodů a v těchto bodech odečtěte průměrné hodnoty teplot v lednu 2014
- vyzkoušejte interpolační metody: IDW, Spline a Natural Neigbor, otestujte změny v nastavených parametrech
Postup cvičení:
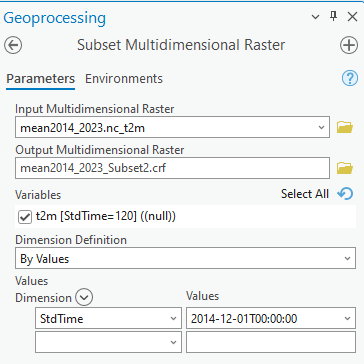
- podle postupu uvedeného ve cvičení 2 si importujte do prostředí AcrGIS Pro soubor mean2014_2023.nc. V menu Multidimensional si nastavte datum na 1.12.2014 (průměrné teploty v prosinci 2014). Pro účely tohoto cvičení potřebujeme pouze tento jeden rastr, proto v menut Multidimensional – Data management zvolte možnost Subset. Zde je nutné definovat dimenzi pomocí hodnoty v datu. Vytvoří se soubor s příponou .crf. Jedná se o formát používaný v ArcGIS Pro pro ukládání rastrových funkcí a řetězců funkcí (raster function chains).
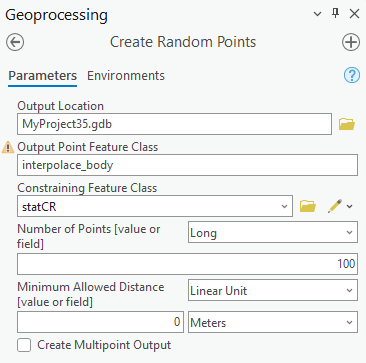
- pomocí nástroje Create Random Points vytvořte 100 bodů náhodně rozmístěných na území České republiky. Jako omezení zde bude sloužit hranice ČR.
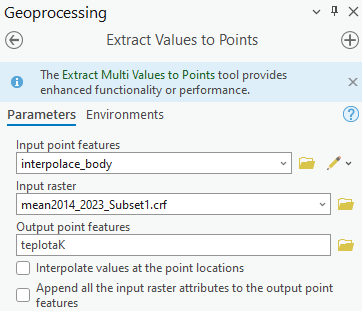
- hodnoty z rastru teplot v prosinci 2014 pak odečtete v jednotlivých bodech pomocí Extract Values to Points. Průměrná teplota je uvedena v Kelvinech, proto si vytvořte nový atribut a hodnoty převeďte na stupně Celsia.
- Explorační analáza dat – popisnou statistiku pro atribut s průměrnou teplotou je možné si nechat spočítat přímo v atributové tabulce. Po kliknutí na název sloupce se objeví možnost Statistics. Interpretujte získané výstupy.
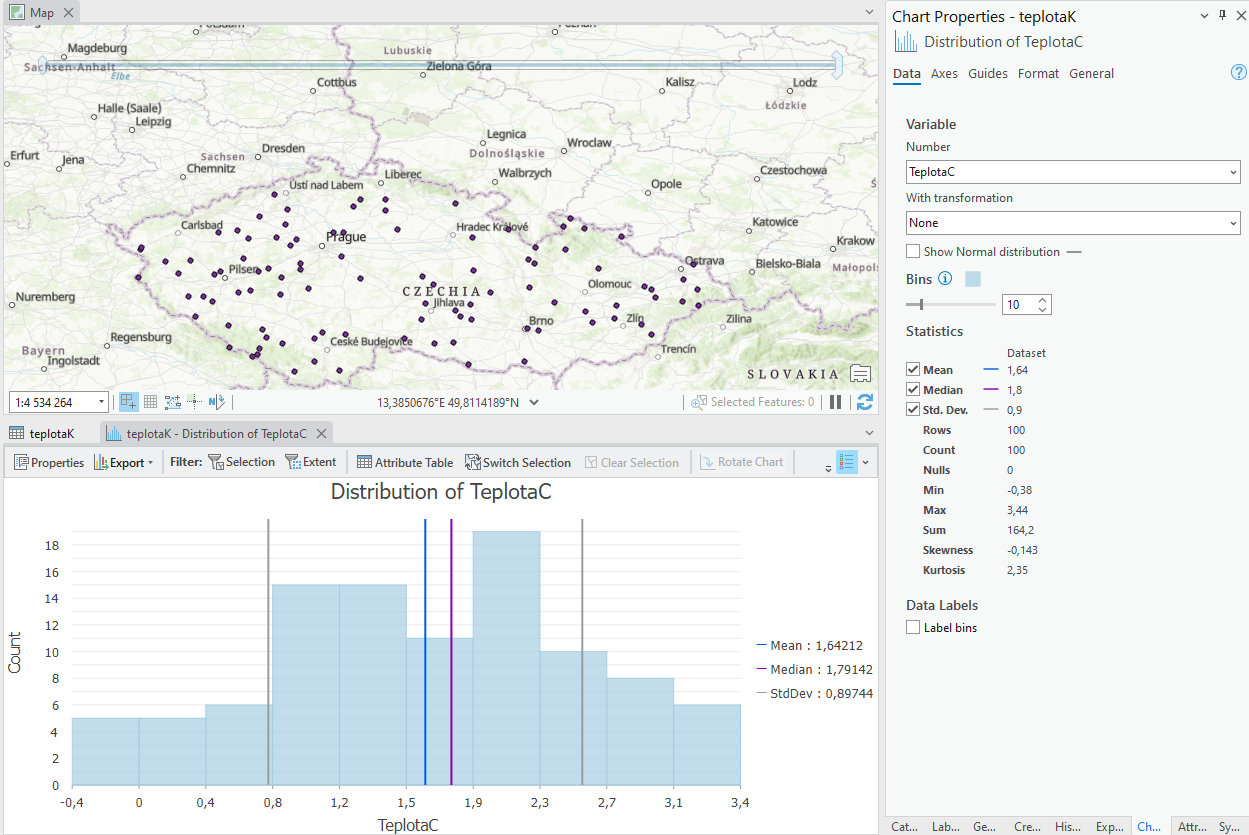
- Explorační analýza dat – další možnosti jsou dostupné po kliknutí pravého tlačítka myši na vrstvu s body a zvolení možnosti Create Chart. Vyzkoušejte si další grafy z nabídky např. krabicový graf.
- Interpolační metody – dostupné interpolační metody naleznete v toolboxu Spatial Analysis Tools – Interpolation. Vyzkoušejte si metodu IDW, Spline a Natural Neighbor, otestujte vliv jednotlivých parametrů na výsledky interpolace.
- Hodnocení přesnosti interpolace – přesnost jednotlivých metod lze určit pomocí např. manuální křížové validace nebo si vypomoci nástrojem Geostatistical Wizard v menu Analysis. Vyberte IDW jako metodu interpolace. V rámci Wizardu použijte možnost cross-validation a vygenerujte report chyb.
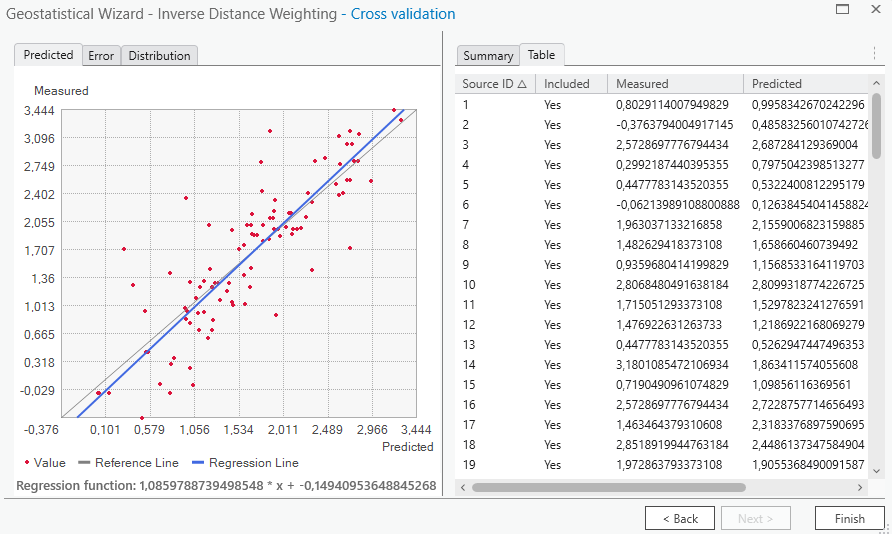
Hodnocení přesnosti interpolace
Existuje několik metod a metrik, které lze použít k hodnocení přesnosti interpolace:
1. Cross-validation (Křížová validace)
- Leave-One-Out Cross-Validation (LOOCV): Tento postup zahrnuje postupné vynechání každého bodu z datasetu, provedení interpolace pomocí zbývajících bodů a porovnání interpolované hodnoty s vynechanou skutečnou hodnotou. Tento proces se opakuje pro všechny body a poskytuje odhad chyby interpolace.
2. Root Mean Square Error (RMSE)
- RMSE je jednou z nejběžněji používaných metrik pro hodnocení přesnosti interpolace. Měří průměrnou velikost chyb mezi skutečnými a interpolovanými hodnotami.
3. Mean Absolute Error (MAE)
- MAE je průměr absolutních chyb mezi skutečnými a interpolovanými hodnotami.
4. Manuální Cross-validation
Pro manuální křížovou validaci můžete postupovat následujícím způsobem:
- Rozdělení dat: Rozdělte svá data na trénovací a validační sady. Například můžete náhodně vybrat 20 % dat jako validační sadu a zbytek jako trénovací sadu.
- Interpolace pomocí trénovací sady: Použijte nástroj IDW v toolboxu Spatial Analyst na trénovací sadu dat.
- Výpočet chyb pro validační sadu: Získané interpolované hodnoty porovnejte s hodnotami z validační sady.