CV06 – Prostorová autokorelace
Prostorová autokorelace
Prostorová autokorelace vyjadřuje míru, do jaké je výskyt určitého jevu v prostoru závislý na výskytu tohoto jevu v blízkém okolí, a je tak kvantitativním vyjádřením prostorové závislosti. Ta je ve své podstatě základním konceptem geografie a úzce souvisí s prvním zákonem geografie formulovaným Toblerem, který konstatuje, že „všechno souvisí se vším, ale bližší věci spolu souvisejí více než vzdálenější“.
Prostorovou autokorelaci lze měřit několika odlišnými prostorovými autokorelačními statistikami popisujícími podobnost blízkých pozorování v závislosti na skutečnosti, zda se jedná o diskrétní či spojitou proměnnou. Dostupné jsou také různé druhy testů prostorové autokorelace v prvotních datech a v regresních reziduích.
Average Nearest Neighbor
Základním nástrojem pro posouzení prostorové autokorelace je funkce Average Nearest Neighbor.
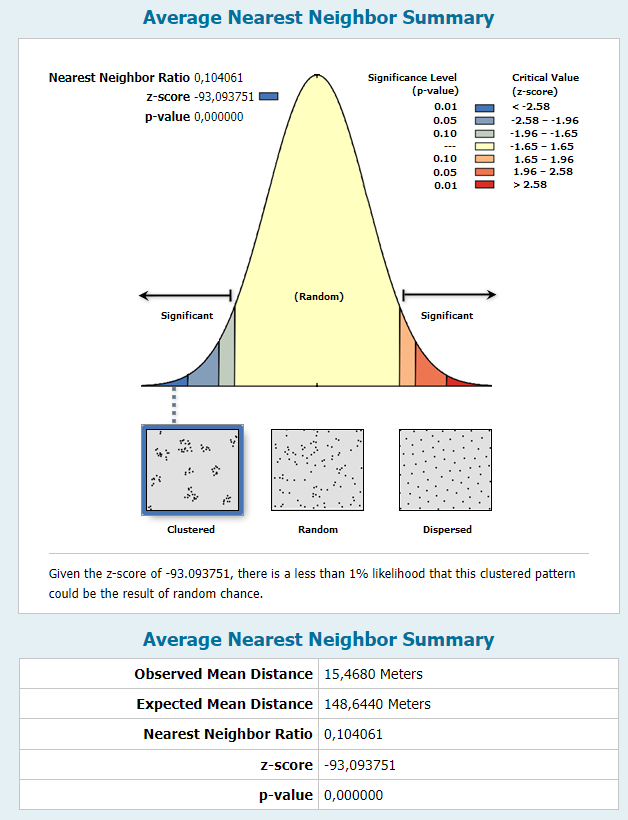
Metoda vypočítá index nejbližšího souseda založený na průměrné vzdálenosti jednotlivých prvků od nejbližšího sousedního prvku. Výpočet je provedený z těžiště každého prvku. Poté je vypočtena průměrná vzdálenost všech nejbližších sousedů a následně dále porovnávána. V případě, že průměrná vzdálenost je menší než hypotetická hodnota náhodné distribuce prvků, vykazují analyzované prvky shlukování. V opačném případě, pokud je průměrná hodnota větší než hypotetická, jsou data považována za rozptýlená. Nulová hypotéza udává, že vrstva nebo hodnoty ve vrstvě vykazují statisticky náhodný vzorek.
Princip nástroje Average Nearest Neighbor
- Výpočet vzdáleností: Nástroj vypočítá vzdálenosti mezi každým bodem a jeho nejbližším sousedem.
- Průměrná nejbližší vzdálenost: Poté se vypočítá průměrná nejbližší vzdálenost pro všechny body.
- Porovnání s náhodným rozložením: Tento výsledek se porovnává s očekávanou průměrnou nejbližší vzdáleností, pokud by body byly rozmístěny zcela náhodně.
- Výpočet z-skóre a p-hodnoty: Nástroj vypočítá z-skóre a p-hodnotu pro určení statistické významnosti zjištěného vzoru.
Výsledkem je:
- Index nejbližšího souseda (Nearest Neighbor Index – NNI): Poměr průměrné nejbližší vzdálenosti k očekávané průměrné nejbližší vzdálenosti.
- NNI > 1: Body jsou více rozptýlené, než by bylo očekáváno při náhodném rozložení.
- NNI < 1: Body jsou více shlukované, než by bylo očekáváno při náhodném rozložení.
- NNI = 1: Body jsou rozmístěny náhodně.
- Z-skóre: Míra standardní odchylky od očekávané průměrné nejbližší vzdálenosti.
- Vysoké kladné z-skóre: Silná indikace rozptylu (body jsou rozptýlené).
- Vysoké záporné z-skóre: Silná indikace shlukování (body jsou shlukované).
- Z-skóre kolem 0: Indikace náhodného rozložení.
- P-hodnota: Pravděpodobnost, že pozorovaný vzor je výsledkem náhody.
- Nízká p-hodnota (např. < 0,05): Výsledek je statisticky významný, což znamená, že je velmi nepravděpodobné, že by pozorovaný vzor byl výsledkem náhody.
- Vysoká p-hodnota: Výsledek není statisticky významný, což znamená, že pozorovaný vzor by mohl být výsledkem náhody.
Interpretace výsledků:
- Shlukování (NNI < 1, nízké z-skóre, nízká p-hodnota): Body vykazují tendenci ke shlukování, což může znamenat, že určité oblasti jsou více atraktivní pro umístění bodů nebo existují vlivy, které způsobují shlukování.
- Rozptyl (NNI > 1, vysoké z-skóre, nízká p-hodnota): Body vykazují tendenci k rozptylu, což může naznačovat, že existují faktory, které způsobují rovnoměrnější rozmístění bodů.
- Náhodné rozmístění (NNI ≈ 1, z-skóre blízko 0, vysoká p-hodnota): Rozložení bodů nevykazuje žádný specifický vzor, což znamená, že body jsou umístěny náhodně bez vlivu vnějších faktorů.
Spatial Autocorrelation (Moran´s I)
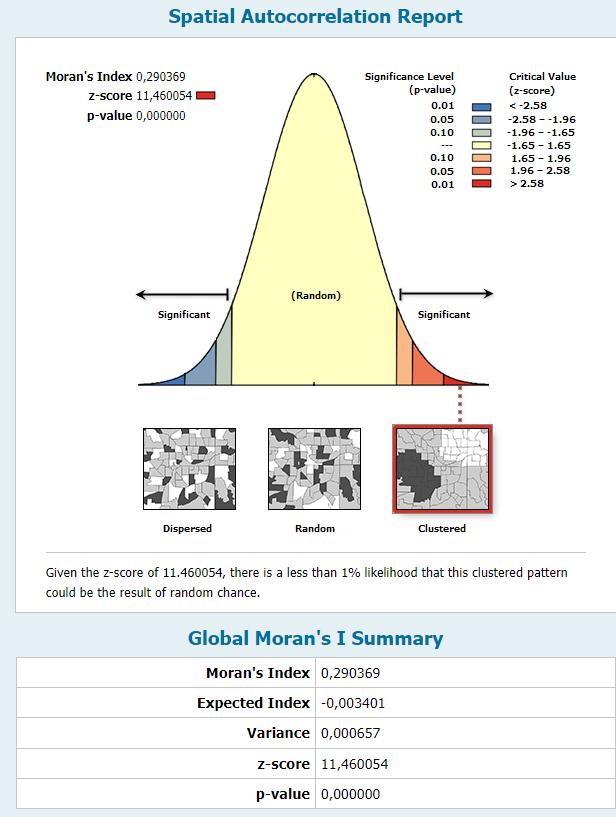
Výstupem nástroje Prostorová autokorelace (kritérium Moran I) (Spatial Autocorrelation (Moran’s I)) je jedna sada hodnot pro celou vstupní datovou sadu: Z-skóre, p-hodnota a tzv. Moranův index. Tento nástroj je velmi užitečný pro prostorové analýzy, kde je potřeba zjistit, zda a jak se hodnoty atributů geograficky shlukují nebo rozptylují, což může být důležité například při analýze prostorových vzorů zločinu, výskytu nemocí, distribuce přírodních zdrojů a dalších fenoménů.
Výsledkem je:
- Hodnota Moranova I: Měří prostorovou autokorelaci.
- Hodnota Moranova I > 0: Indikuje pozitivní autokorelaci (shlukování podobných hodnot).
- Hodnota Moranova I < 0: Indikuje negativní autokorelaci (rozptyl podobných hodnot).
- Hodnota Moranova I = 0: Indikuje náhodné rozmístění hodnot bez prostorové autokorelace.
- Z-skóre: Indikuje, jak daleko je pozorovaná hodnota Moranova I od očekávané hodnoty v jednotkách standardní odchylky.
- Vysoké kladné z-skóre: Silná indikace pozitivní autokorelace.
- Vysoké záporné z-skóre: Silná indikace negativní autokorelace.
- Z-skóre kolem 0: Indikace náhodného rozmístění.
- P-hodnota: Pravděpodobnost, že pozorovaný vzor je výsledkem náhody.
- Nízká p-hodnota (např. < 0,05): Výsledek je statisticky významný, což znamená, že je velmi nepravděpodobné, že by pozorovaný vzor byl výsledkem náhody.
- Vysoká p-hodnota: Výsledek není statisticky významný, což znamená, že pozorovaný vzor by mohl být výsledkem náhody.
Interpretace výsledků
- Pozitivní autokorelace (Moranův I > 0, vysoké kladné z-skóre, nízká p-hodnota): Ukazuje, že podobné hodnoty mají tendenci být blízko sebe. To znamená, že vysoké hodnoty jsou blízko jiných vysokých hodnot a nízké hodnoty jsou blízko jiných nízkých hodnot.
- Negativní autokorelace (Moranův I < 0, vysoké záporné z-skóre, nízká p-hodnota): Ukazuje, že podobné hodnoty mají tendenci být daleko od sebe. To znamená, že vysoké hodnoty jsou blízko nízkých hodnot a naopak.
- Náhodné rozmístění (Moranův I ≈ 0, z-skóre kolem 0, vysoká p-hodnota): Indikuje, že neexistuje žádný prostorový vzor a hodnoty jsou rozmístěny náhodně.
V případě pozitivní autokorelace budeme chtít vyzkoumat, kde shluky jsou. Můžeme hledat, kde jsou shluky vysokých/nízkých hodnot (Hot spot analýza (Getis-Ord Gi*)) nebo kde statisticky významně sousedí vysoké a nízké (extrémní) hodnoty (Analýza homogenních a heterogenních shluků (Cluster and Outlier Analysis (Anselin Local Moran’s I)).
Data pro cvičení
- stáhněte si informace o kriminalitě ve formátu *.zip v obci Ostrava za rok 2023 ze stránek: https://kriminalita.policie.cz/
- přečtěte si jaké informace jsou v těchto datech obsaženy: https://kriminalita.policie.cz/napoveda/#/
Postup cvičení
- data o kriminalitě ve formátu *.csv si přidejte do prostředí ArcGIS Pro (XY Table to Point) a vytvořte z nich bodovou vrstvu
- originální data jsou poskytována v souřadnicovém systému WGS84, transformujte je proto do S-JTSK (Project)
- atributovým dotazem si vyberte z dat pouze tyto události (atribut types): krádeže vloupáním (č. 18), krádeže součástek a věcí z aut, včetně vloupání (č. 41) a krádeže na osobách (č. 43), vyexportujte do nové vrstvy
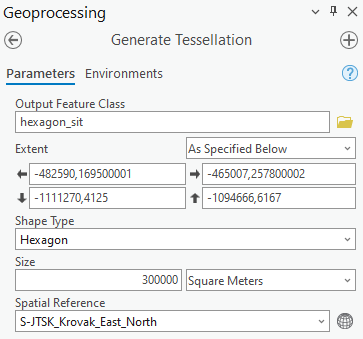
- abyste získali smysluplnější přehled, vytvořte si hexagonovou mřížku (Generate Tessellation) nad bodovými daty, vyberte prostorovým dotazem pouze ty hexagony, kde došlo k události a vypočítejte počet událostí v jednotlivých hexagonech (Spatial Join)
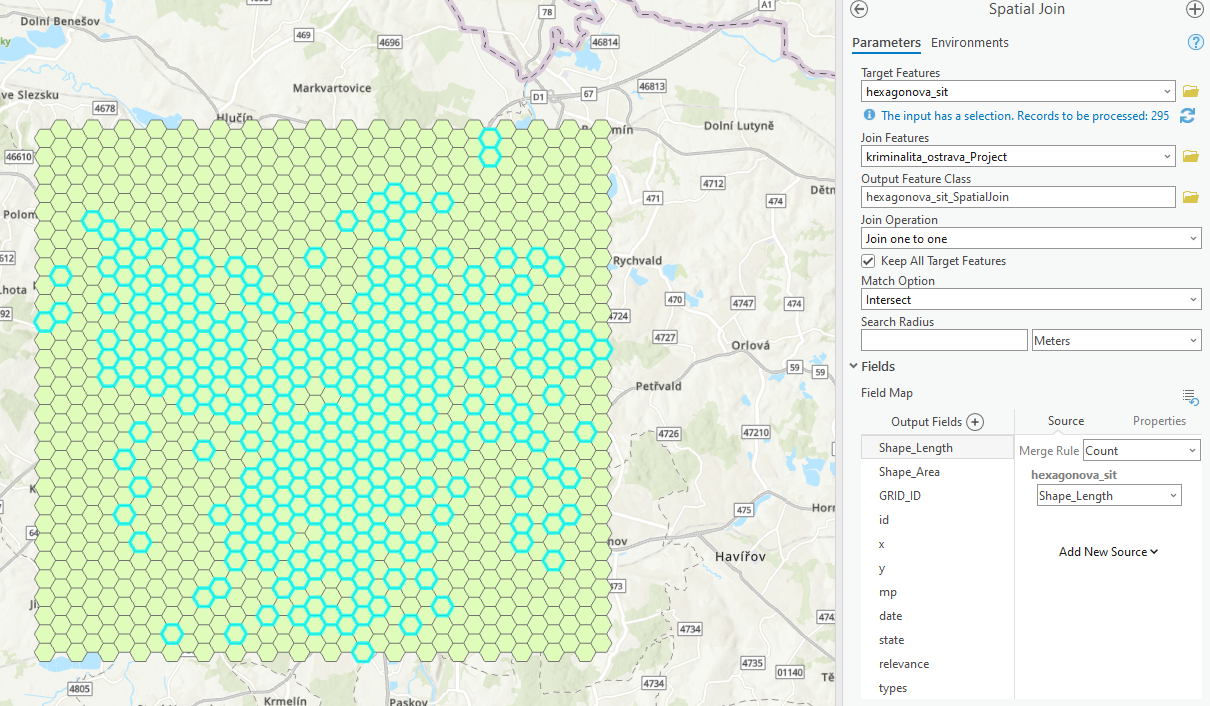
- výsledkem bude hexagonová síť, která bude obsahovat pouze polygony, kde došlo k nějaké události a jejich počty, využijte symbologii pro zobrazení počtu událostí
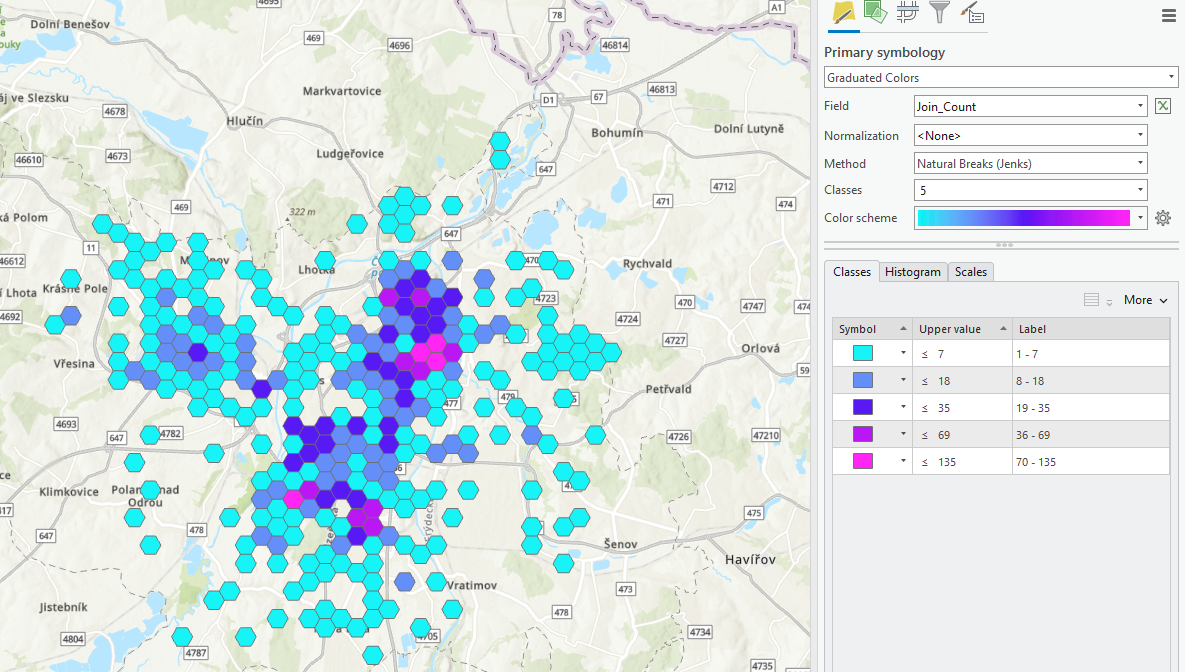
- vypočítejte pomocí nástroje Average Nearest Neigbor index nejbližšího souseda, p-value a z-skóre, vyhodnoťte a okomentujte výsledek
- s využitím nástroje Spatial Autocorrelation (Moran´s I) získejte hodnoty Moranova indexu, p-value a z-skóre, vyhodnoťte a okomentujte výsledek
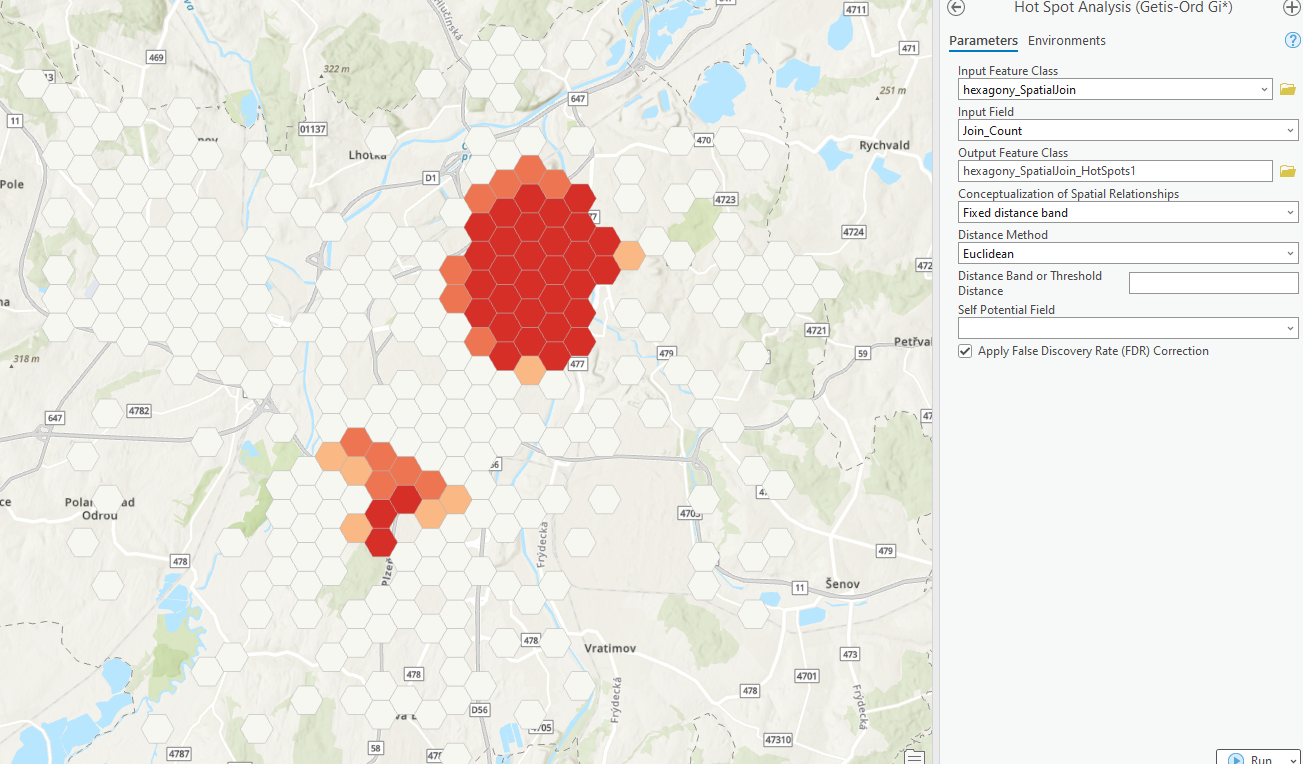
- jelikož prostorová autokorelace je pozitivní, prozkoumejte, kde shluky jsou – Hot Spot Analysis s využitím korekce FDR. Nástroj Hot Spot Analysis (Getis-Ord Gi*) v ArcGIS Pro slouží k identifikaci statisticky významných shluků vysokých nebo nízkých hodnot (hot spots a cold spots) v prostorových datech. Korekce FDR (False Discovery Rate) je důležitý krok při této analýze, protože pomáhá kontrolovat chybovost při vícečetném testování hypotéz. FDR je statistický přístup, který se používá k redukci množství falešně pozitivních výsledků, což jsou případy, kdy test identifikuje něco jako statisticky významné, když ve skutečnosti to tak není.
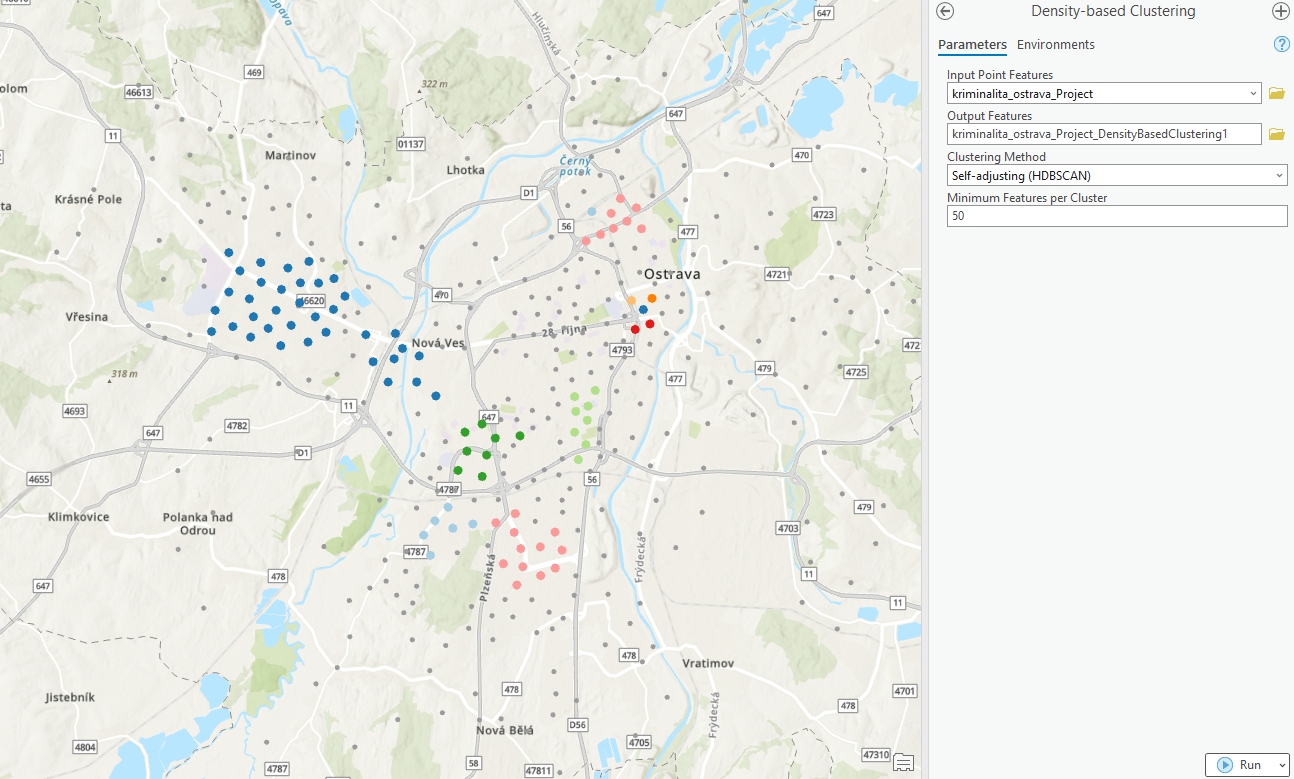
- další z možností k identifikaci shluků na základě hustoty bodů je využití nástroje Density-based Clustering. Tento nástroj je užitečný pro rozpoznávání oblastí s vysokou koncentrací bodů (clustery) a oblastí s nízkou koncentrací bodů (noise). Jeden z nejpoužívanějších algoritmů pro density-based clustering je DBSCAN (Density-Based Spatial Clustering of Applications with Noise). Každému bodu je přiřazen identifikátor clustru (Cluster ID), který určuje, do kterého clustru bod patří. Body, které nepatří do žádného clustru a jsou považovány za šum (noise), mají speciální označení, obvykle -1 nebo NULL.
Zadání samostatného programu
- proveďte analýzu dat o kriminalitě pro vaší obec. V případě, že bydlíte v Ostravě, vyberte si jinou obec nebo zpracujte jiný rok než byl zpracován v rámci cvičení
- výstupem tohoto programu bude dokument, který bude obsahovat okomentované výsledky nástrojů pro prostorovou autokorelaci pro vaší obec
- dále bude obsahovat 3 mapové výstupy – hexagonová síť s počty událostí, výstup Hot Spot Analysis a výstup Density Based Clustering, rovněž i tyto mapové výstupy budou náležitě okomentovány